What Is LLM Optimization (LLMO) and Why It Matters for SEO
There’s a common misconception that large language models (LLMs) are simply smarter versions of search engines like Google. This notion is not only inaccurate but also limits the potential for optimizing content for LLM visibility. Unlike search engines that retrieve information, LLMs generate answers based on compressed patterns from their training data. Understanding this distinction is critical for anyone looking to optimize content for LLMs.
LLMs don’t pull answers from a real-time database. Instead, they generate responses by predicting the next token in a sequence based on the patterns they’ve learned. If you don’t grasp this, your attempts at optimizing for LLM visibility will likely fall flat. Let’s dive into how LLMs work and why traditional SEO thinking is often ineffective in this new landscape.
How LLMs Actually Work: The Foundation Layer
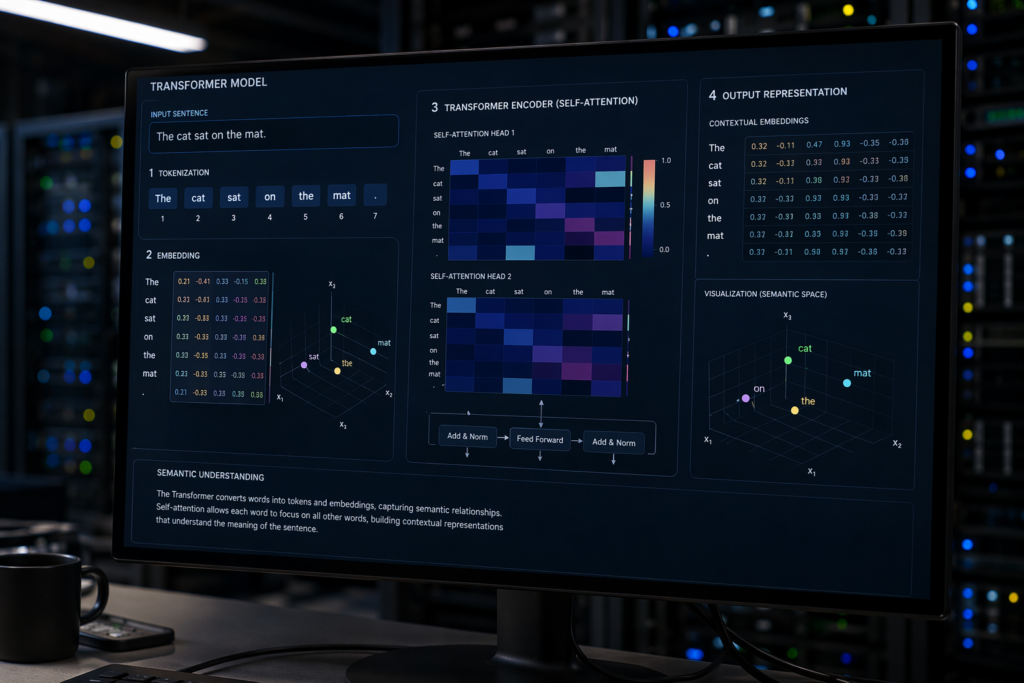
At the core of LLMs lies a sophisticated architecture known as the Transformer model. This model processes text by converting words into tokens, which are then transformed into embeddings. These embeddings carry the semantic information needed for the model to understand context and make predictions.
The process involves utilizing an attention mechanism to weigh the importance of each token in relation to others. This allows the model to focus on specific parts of the input text when generating a response. The goal is to predict the next token, not to retrieve existing data. This probabilistic approach makes LLMs more akin to compressors of internet knowledge rather than retrieval systems.
LLMs are fundamentally about pattern recognition. They don’t have a database from which to fetch answers. Instead, they generate responses based on the probability of token sequences, which are derived from their training data. This foundational understanding is crucial for anyone aiming to optimize content for LLM visibility.
Where “Retrieval” Actually Enters the System
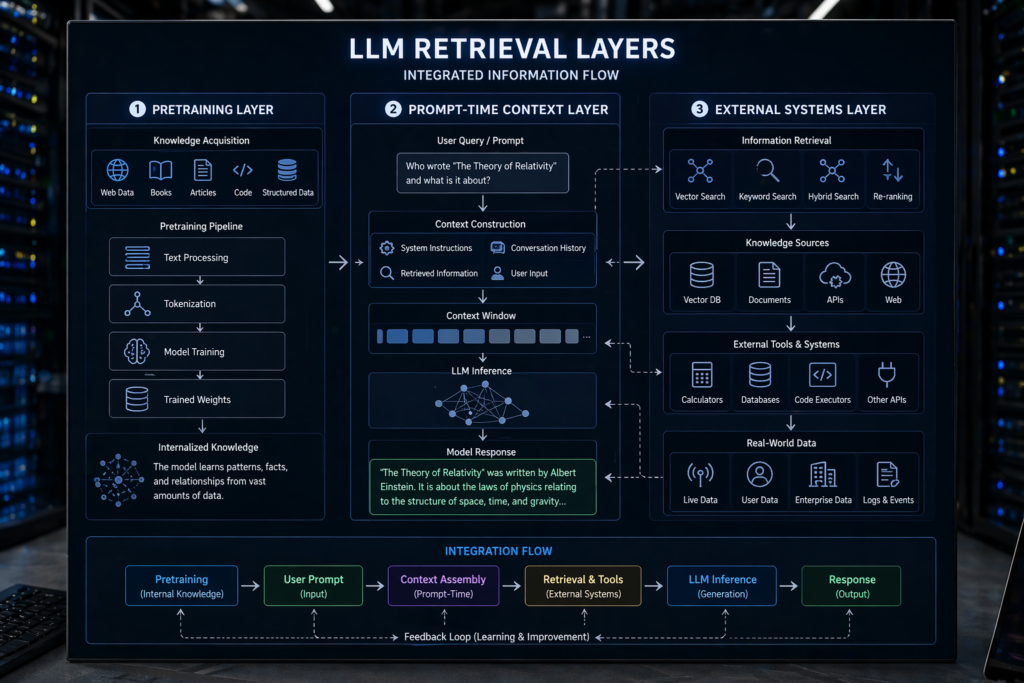
While LLMs themselves don’t retrieve information, retrieval can be integrated into the system in various ways. The concept of retrieval can be broken down into three layers: pretraining, prompt-time context, and external retrieval systems.
-
Pretraining (Static Knowledge)
During the pretraining phase, LLMs are exposed to vast amounts of data from books, websites, and code. This data serves as the foundation for pattern recognition. However, it’s important to note that this knowledge is static. Once trained, the model doesn’t update its knowledge base unless retrained, making it inherently stale.
-
Prompt-Time Context (In-Context Retrieval)
In-context retrieval occurs when a user provides input to the model. The model uses this input as immediate context, acting as a temporary working memory. This allows LLMs to generate responses that are relevant to the user’s query, but the retrieval is limited to what the user provides.
-
External Retrieval Systems (Real Game-Changer)
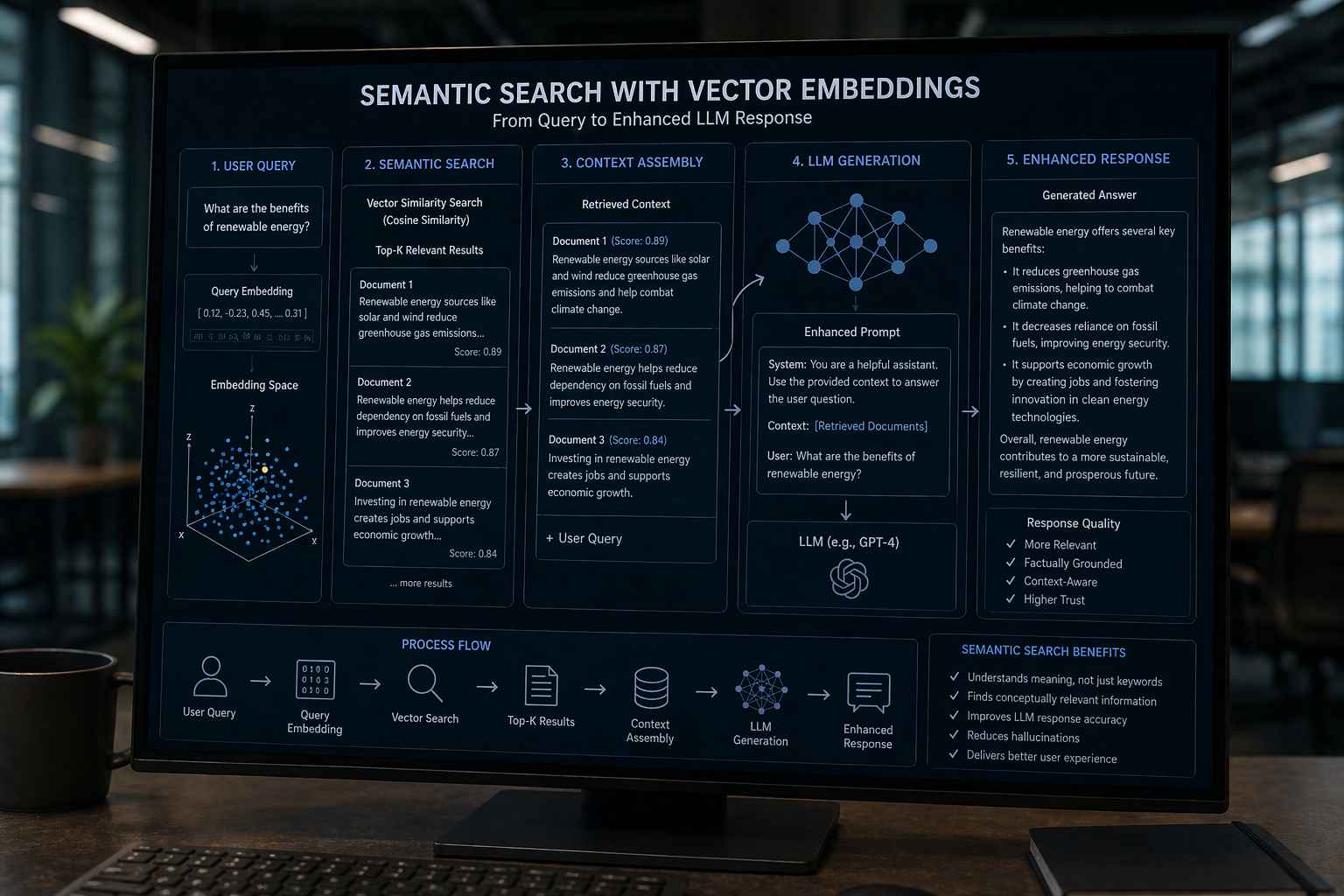
The most significant development in retrieval comes from external systems like Retrieval-Augmented Generation (RAG). These systems utilize vector embeddings to perform semantic searches, vastly different from traditional keyword searches. The process involves transforming a query into an embedding, matching it with similar vectors, and injecting the results into the prompt. The LLM then generates a response based on this enriched context.

Why Traditional SEO Thinking Breaks Here
Traditional SEO strategies are largely ineffective when it comes to optimizing for LLMs. The concepts of ranking, keyword density, and backlinks are not directly applicable. LLMs do not rank content in the way search engines do; they prioritize semantic clarity and structured meaning.
Keyword density, a staple of SEO, becomes irrelevant in the context of LLMs. Instead, the focus should be on making content retrieval-friendly, not just crawler-friendly. Backlinks may serve as an indirect signal of authority, but they are not a primary factor in LLM content visibility.
To optimize for LLMs, content must be structured in a way that enhances semantic clarity. This involves creating content that is organized, precise, and easy for models to interpret.
How LLMs Decide What to “Use” in Answers
When generating responses, LLMs rely on several selection signals. Semantic similarity is critical; the model looks for an embedding match to ensure the content is relevant to the query. Context fit also plays a role, aligning the generated response with the user’s intent.
Authority patterns, which are frequent co-occurrences in training data, can influence the model’s choices. However, it’s essential to note that LLMs don’t choose the best content; they choose the most statistically compatible content. This means that content must be not only informative but also statistically relevant to the model’s training data.
Clarity and chunkability are additional factors. Clear, concise, and well-structured content can be more easily processed by LLMs, increasing the likelihood of being used in generated responses.
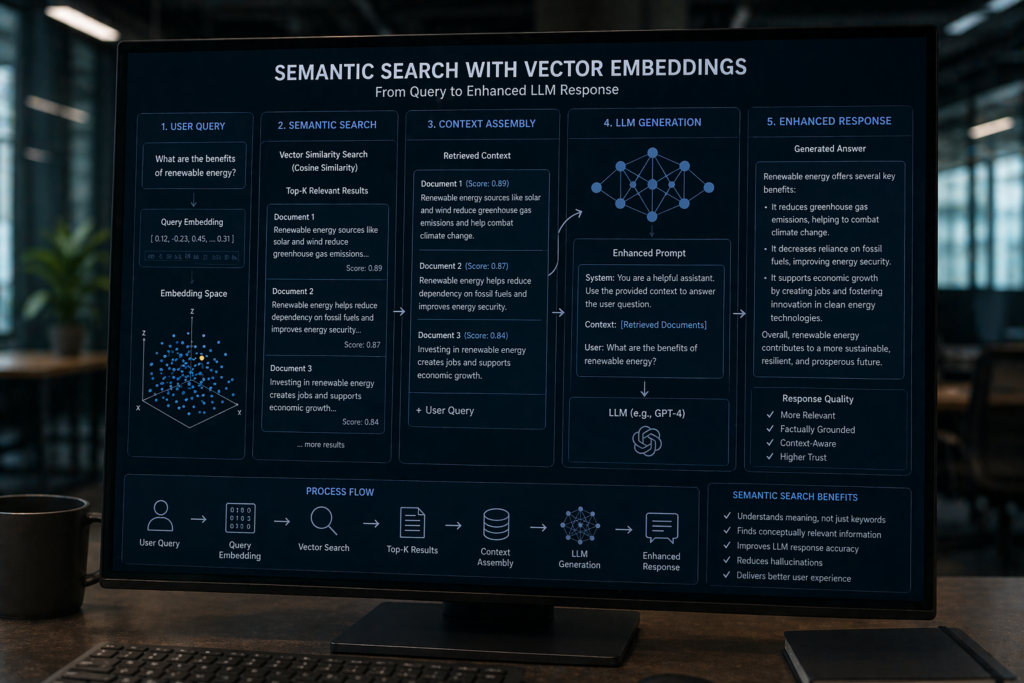
LLMO Framework: Optimizing for Retrieval, Not Ranking
To optimize for LLMs, a new framework called LLM Optimization (LLMO) is necessary. This approach focuses on retrieval rather than traditional ranking metrics. It involves several key pillars:
-
Chunk-Level Optimization
Content should be divided into retrievable blocks rather than long essays. Each section should function as a standalone answer, enhancing its likelihood of being used by LLMs.
-
Semantic Density > Keyword Density
Instead of repeating keywords, focus on using concept clusters. This increases the semantic richness of the content, making it more appealing to LLMs.
-
Explicitness Wins
Define terms clearly and avoid ambiguity. Clear definitions improve the model’s ability to understand and use the content effectively.
-
Structured Knowledge Patterns
Utilize lists, comparisons, and frameworks. Q&A formatting can also enhance content structure, making it easier for LLMs to process.
-
Entity-Based Writing
Incorporate recognizable entities such as tools, concepts, and frameworks. This helps align embeddings, increasing the content’s relevance to the model.
Future of Retrieval in LLMs
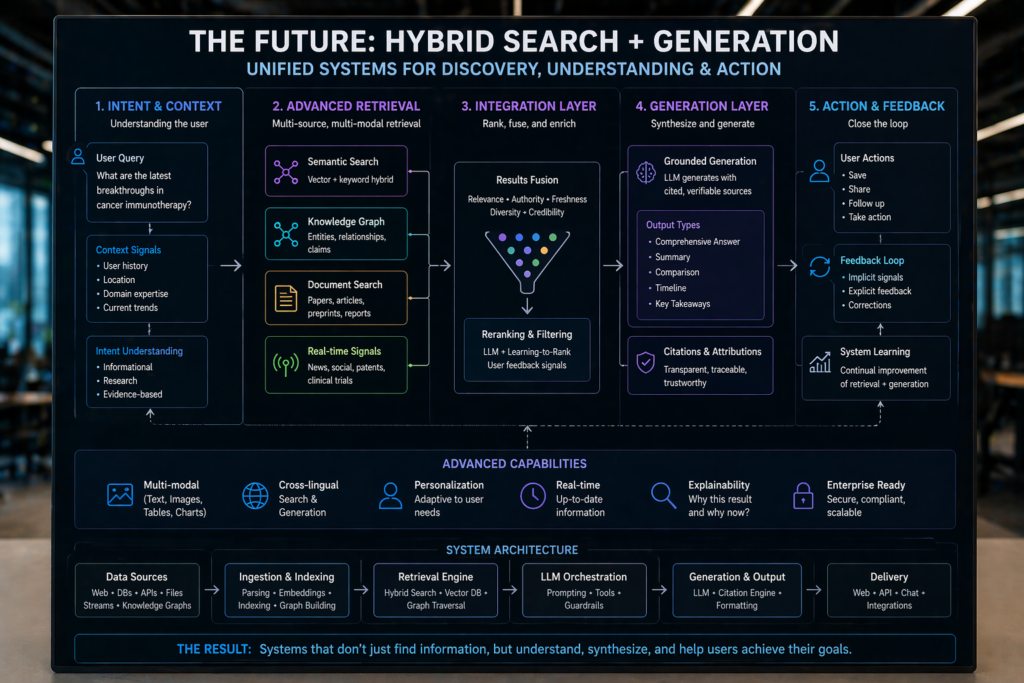
The future of retrieval in LLMs is promising, with several exciting developments on the horizon. Hybrid systems that merge search and generation capabilities are emerging, offering more comprehensive solutions.
Personal context layers and real-time retrieval APIs are also gaining traction, providing more dynamic and personalized interactions. Additionally, proprietary knowledge bases are on the rise, offering specialized and updated information to enhance LLM outputs.
Why Retrieval-Structured Content Matters
If your content isn’t structured for retrieval, it won’t exist in AI-generated answers. As LLMs continue to evolve, optimizing for retrieval will become increasingly crucial. Consider leveraging tools and platforms that analyze semantic visibility to ensure your content remains relevant in this new landscape.
Further reading:
AI writing tools — Guide on AI writing tools
People Also Ask:
Q1. How do LLMs differ from traditional search engines?
A1. LLMs generate responses based on learned patterns rather than retrieving information from a database. They predict the next token in a sequence, making them probabilistic rather than retrieval-based.
Q2. What is the role of semantic similarity in LLM responses?
A2. Semantic similarity ensures that the content generated by LLMs is relevant to the user’s query. It involves matching embeddings to align the response with the query’s intent.
Q3. Why is keyword density irrelevant for LLM optimization?
A3. LLMs prioritize semantic clarity over keyword density. Instead of focusing on repeated keywords, content should be structured to enhance semantic richness and clarity.
Q4. How can content be optimized for LLM retrieval?
A4. Content should be organized into retrievable blocks, use concept clusters, and be explicit in definitions. Structured knowledge patterns and entity-based writing also improve retrieval efficiency.
Q5. What future developments are expected in LLM retrieval?
A5. Future advancements include hybrid systems merging search and generation, personal context layers, real-time retrieval APIs, and proprietary knowledge bases, enhancing LLM capabilities.


